Event Streaming Platforms: Kafka - A Hands-On Tutorial

Ever wondered how systems such as Apache Kafka [Open Source], Google Pub/Sub [Google Managed], Azure Event Hubs [Azure Managed], etc. functions?
These distributed messaging/event streaming platform-systems facilitate the the near-realtime data streaming and parallel processing for ETL and analytical capabilities.
The practical applications include ability to build:
- Near-real time data pipelines - E.g. Geolocation updates from mobile phones, Shipping orders, Order Deliveries
- Large scale data pipelines where the batch jobs can be too expensive - E.g. Payment transactions, Sensor measurements from IoT devices or medical equipment.
Simply put, these are message transportation systems that are highly performant and resilient. This post will help you understand the components of the ELK stack and will get you up and running to process logs on your local machine. Kafka, being a stateful system gives the ability to read the stream at different positions and different speeds and replay the messages from the past (at least from the set expiry time).
Components of Kafka
Apache Kafka consists of several key components that work together to provide a scalable and distributed streaming platform.
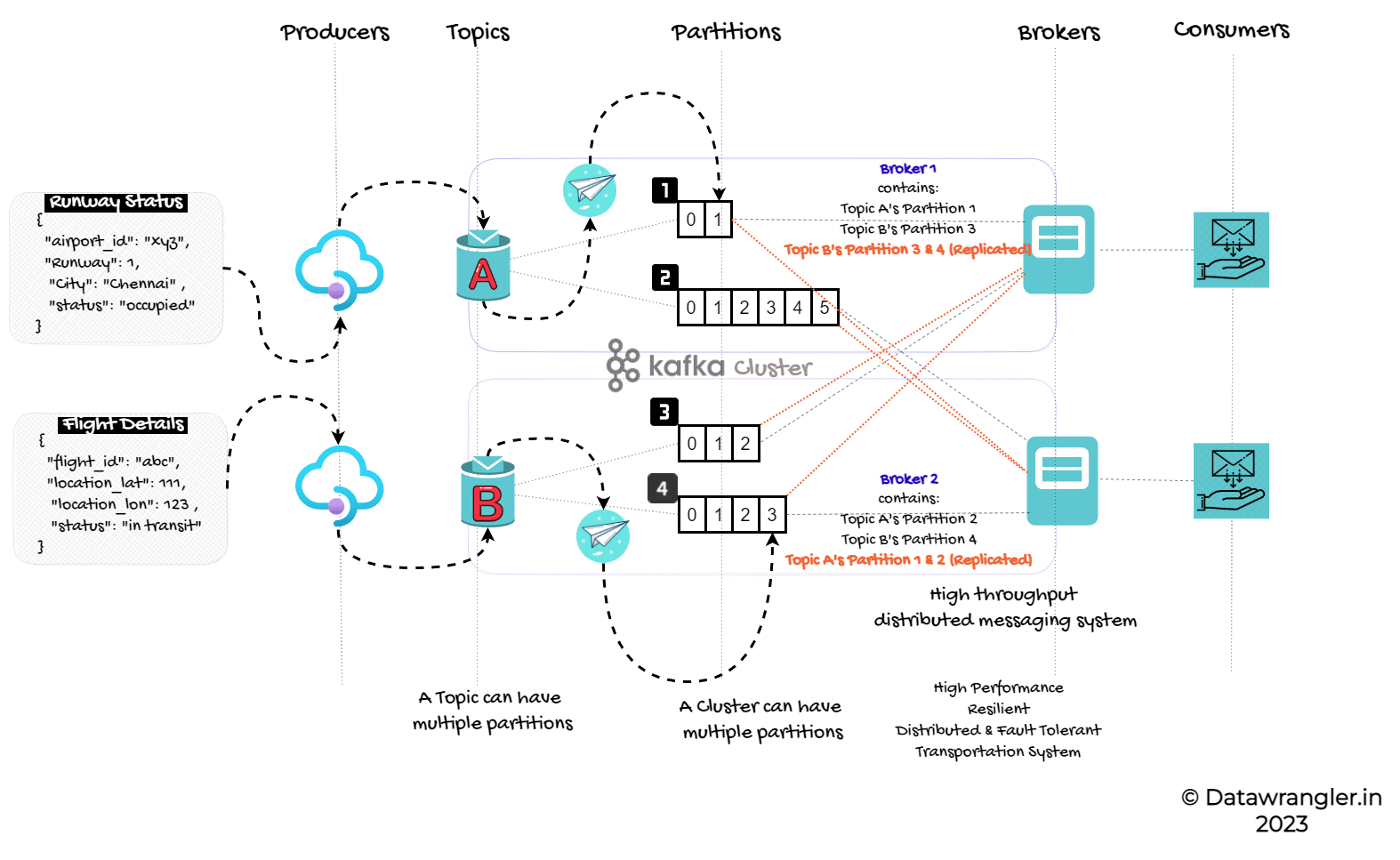
The main components of Kafka are mentioned as follows:
Topics
Topics hold the logical stream of data. It is synonymous to a folder in a filesystem or a table in a database. The events are synonymous to the files in a folder or the rows in a table
You can have any number of topics. Applications write directly or publish the messages to the topics. Internally, topics are made up of multiple partitions and the packets are distributed for resilience across multiple nodes (also known as Brokers).
Partitions & Offsets
As mentioned earlier, topics are stored as multiple partitions across different nodes for data resilience. The messages are stored within a partition, gets incremental id’s - known as offsets.
The offsets are incremental and once assigned, offset can never be re-assigned ever again even if the messages get flushed.
The sorting order of the offsets are maintained inside the partition but not guaranteed when sent across different partitions.
Data is retained in the offsets only for a limited time (Default is 1 week). This expiry time can be modified to other durations too.
Data is immutable and can’t be manipulated once after it has been written to a partition.
Data is assigned to a partition randomly unless the partition is forcefully defined.
But, does it matter if the partition is randomly assigned?
Brokers
Event streaming platforms are multi-node distributed system containing multi-noded clusters. The nodes of the clusters are known as brokers. At least three nodes/brokers are required to make a perfectly functioning cluster. The data is randomly distributed and replicated across these brokers.
Like any other distributed system, connecting to a single broker (Bootstrap Broker) will give access to the entire cluster. Topics are universally assigned and distributed across the brokers. However, the data distribution across the number of brokers is decided based on the replication factor. This brings the resilience into the picture, making sure that: If a broker is down, another broker can serve the data.
Replication Golden Rule: Even though multiple brokers can have the copy of the data, only one of the broker can be a leader for a given partition. The other brokers will synchronize and replicate the data. If the leader goes down, one of the followers will get elected to become the leader.
Each partition has a leader and multiple ISRs (in-sync replica). Distribution coordination services such as Apache Zookeeper will decide on this and take care of replication.
Publishing Data to Kafka (Write)
To write data to Apache Kafka, you need to create a producer application that connects to the Kafka cluster and publishes messages to the desired Kafka topic.
Producers
Applications known as Producers writes the data to topics. They know to which broker and partition to write to. During failures, the producers will auto recover. The load is balanced across the brokers. When sending the data, if the key is not specified, the producer sends the data to brokers based on round robin.
Data Send Modes
Producers can be configured whether to receive the acknowledgement for data writes. The following are the possible send modes, one of them can be configured for the producers.
| Send Mode | Description | Data Loss | Use-case |
|---|---|---|---|
| acks=0 | Producer won’t wait for acknowledgement - very dangerous but no lag in performance | Possible data loss | Suitable for high volume data transfers |
| acks=1 | Producer will wait for the leader broker to acknowledge | limited data loss | Suitable for data streams related (Widely Used) |
| acks=all | Leader and all other replicas get the data and acknowledge | no data loss but poor performance | Suitable for secure and persisted storages |
Message Keys
If the ordering of the message matters, the message keys are mandatory. For example, consider an ecommerce or a delivery app in which the key can be as order_ids. There are different event types for the processing of an order such as: “ordered”, “shipped”, “in-transit” and “delivered” that is highly crucial to be processed in the same sequence and this is done by assigning to them to the same message key.
Message keys can be a hash, number, string, number, etc. If message key is null, data is sent round robin (i.e. in case of two brokers - first message is sent to broker 1, second message to broker 2, third message to broker 1, etc.).
If a key is null or not provided, the data will be sent to any partition based on round robin.
Subscribing to Data in Kafka (Read)
Applications known as Consumers reads the data from the consumer groups, also known as subscriptions.
Consumers
Consumers read the data from topics. They know which broker to read from. Consumers can auto-recover, in case of failures. Data is read in order within each partition.
In case of consumers reading from multiple partitions, the reading order can be random but however within each partition, the data is read in order.
Consumer Groups
Consumers read from multiple partitions by reading in Consumer Groups. Work is divided among the consumer groups. Internally, Consumers will use a Group Coordinator and a Consumer Coordinator to assign consumers to a partition.
If there are too many consumers and just a few partitions, some of the consumers may be inactive. These inactive consumers can be helpful when one of the consumers go down, so that the inactive consumer can replace the failed consumer.
For Example:
A Dashboard application can have two consumers under a consumer group 1 and can read from three partitions at a time. A notification application can have one consumer reading from multiple partitions at the same time.
Installing Kafka
Setting up Apache Kafka involves:
- Downloading Kafka
- Configuring the Kafka cluster
- Starting the necessary components.
Here’s a high-level overview of the steps to set up Kafka:
Download Kafka:
Go to the Apache Kafka website (https://kafka.apache.org/downloads) and download the desired Kafka version. Extract the downloaded archive file to a directory on your system.
Configure Kafka:
Navigate to the Kafka installation directory and locate the config subdirectory. Modify the configuration files as per your requirements:
config/server.properties: This file contains the configuration for Kafka brokers. You may need to update properties such asbroker.id,listeners,log.dirs, andzookeeper.connect.config/zookeeper.properties: This file contains the configuration for the ZooKeeper server used by Kafka. Update properties such asdataDirandclientPortif necessary.
Starting the Necessary Components
- Start ZooKeeper:
Kafka relies on ZooKeeper for coordination and maintaining cluster state. Start ZooKeeper by executing the following command in a new terminal or command prompt window:
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Keep the ZooKeeper instance running while setting up and using Kafka.
- Start Kafka brokers:
In a separate terminal or command prompt window, start the Kafka brokers by executing the following command:
$ bin/kafka-server-start.sh config/server.properties
You can start multiple brokers if you want to set up a Kafka cluster. In such cases, you need to configure unique properties such as broker.id, listeners, and log.dirs for each broker.
- Create topics:
Kafka uses topics to organize and categorize messages. You can create a topic using the following command:
$ bin/kafka-topics.sh --create --topic <topic_name> --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
Adjust the <topic_name> as desired, and specify the appropriate bootstrap-server (Kafka broker) address, partitions, and replication factor.
- Verify the setup:
To ensure that Kafka is running and the setup is correct, you can use various Kafka command-line tools to produce and consume messages from topics. For example:
Produce messages:
$ bin/kafka-console-producer.sh --topic <topic_name> --bootstrap-server localhost:9092
Consume messages:
$ bin/kafka-console-consumer.sh --topic <topic_name> --bootstrap-server localhost:9092 --from-beginning
These steps provide a basic setup of Kafka for local development and testing purposes. For production environments, additional configurations and considerations are necessary, such as securing the cluster, configuring replication, and setting up additional components like Kafka Connect or Kafka Streams.
This gives you a basic understanding of the Kafka architecture and how to get started. They allow for high-throughput, real-time data streaming and processing across multiple applications and systems. Some of the practical use-cases include: messaging system, large volume log aggregation transport, stream processing, data pipelines, and IoT data processing.